





浅析入门SEO必备知识——网络爬虫
来源:Eidea浏览次数:3636
什么是网络爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁,自动索引,模拟程序或者蠕虫。
这些处理被称为网络抓取或者蜘蛛爬行。很多站点,尤其是搜索引擎,都使用爬虫提供最新的数据,它主要用于提供它访问过页面的一个副本,然后,搜索引擎就可以对得到的页面进行索引,以提供快速的访问。蜘蛛也可以在web上用来自动执行一些任务,例如检查链接,确认html代码;也可以用来抓取网页上某种特定类型信息,例如抓取电子邮件地址(通常用于垃圾邮件)。
一个网络蜘蛛就是一种机器人,或者软件代理。大体上,它从一组要访问的URL链接开始,可以称这些URL为种子。爬虫访问这些链接,它辨认出这些页面的所有超链接,然后添加到这个URL列表,可以称作检索前沿。这些URL按照一定的策略反复访问。

网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件,流程图所示。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1) 对抓取目标的描述或定义;
(2) 对网页或数据的分析与过滤;
(3) 对URL的搜索策略。
抓取目标的描述和定义是决定网页分析算法与URL搜索策略如何制订的基础。而网页分析算法和候选URL排序算法是决定搜索引擎所提供的服务形式和爬虫网页抓取行为的关键所在。这两个部分的算法又是紧密相关的。

上一篇:怎么利用图片做好SEO优化?
下一篇:SEO入坑必备知识--关键词
相关seo研究资讯推荐
- 如何分析网站日志?2018-10-14
- 网站被k了,需要怎么处理?2019-05-14
- seo真的越来越难做了吗?2019-02-19
- 网站SEO优化流程概要2019-02-19
- 我是如何用一篇软文将广州网站改版做到百度首页前三的2019-01-12
- SEO优化中外链建设的13条技巧2019-02-19
成功案例
-
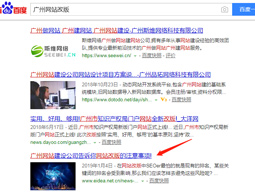
单篇软文关键词优化
-
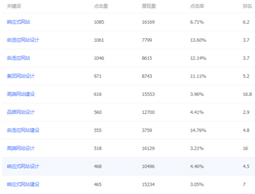
服务别人前得先证明自己的实力
-
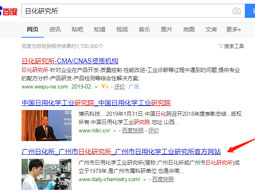
打造日化研究所的行业地位

